The Datacenter and Beyond
The datacenter papers
I should be honest: the three datacenter papers, VL2, FaRM, and eRPC, didn’t stick with me. I don’t remember the details of VL2 at all. I know it came out of Microsoft Research and the original post claimed it was personal because I work on Azure Infra, but that was probably an exaggeration. FaRM and eRPC covered kernel-bypass networking and RDMA, and I’m sure the lectures were good, but I couldn’t tell you what I learned from them.
I think this says something about which knowledge is “sticky” for a practitioner. The philosophy papers (end-to-end, tussle) stuck because they gave me a framework I use in design reviews. The consensus papers stuck because I’ve lived the failure modes. But papers about datacenter network topology and NIC optimization sit at a layer of the stack I don’t interact with directly. They’re important, but they didn’t give me something I could use the following week at work.
What I do remember from this part of the course is a realization that cut across all the datacenter material. We are, inside the datacenter, going against the end-to-end argument. We put a lot of intelligence into the network to reduce congestion and build smarter systems. This makes sense because the end-to-end argument was meant for public infrastructure where you don’t control the endpoints. A datacenter is private infrastructure. You control everything. So the trade-off is different: public networks should be dumb because openness and reliability matter more than performance. Private datacenter networks should be smart because you need performance and you can afford to be smart since you own both sides.
Spanner
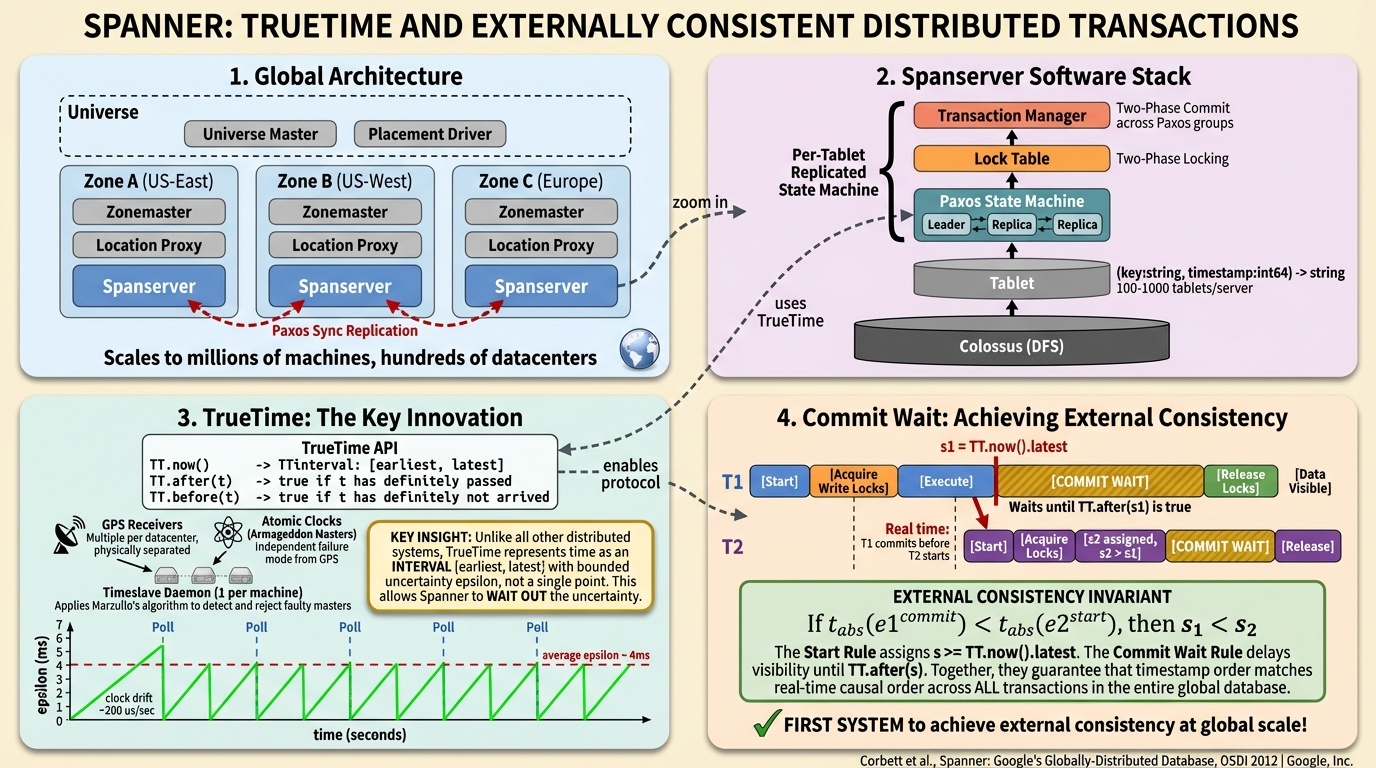
Spanner is Google’s globally distributed database with GPS receivers and atomic clocks in every datacenter, giving every node a bounded uncertainty interval on the current time. Mazières counted the authors and estimated the project cost over a hundred million dollars when you add up the salaries of 20-plus senior Google engineers over five years.
The counterintuitive part is what Spanner does with its time signal. It deliberately slows down. When it assigns a timestamp to a transaction, it sits on the result and waits for the time uncertainty to resolve before sending the reply. A student asked the obvious question: can’t you just reduce the uncertainty? Mazières answered: “If you don’t like how long you have to wait, buy more atomic clocks.”
What stuck with me about Spanner wasn’t the technical details. It was the contrast in engineering culture. Google is like the Porsche of cloud infrastructure. They overengineer things, build custom hardware, hire the best researchers, and produce systems with remarkable performance characteristics. The trade-off is cost and complexity. It took a hundred million dollars and five years to get Spanner. At my company, the approach is different. We’re more like Ford. We ship things to market, iterate, and compete on breadth and enterprise relationships. Both approaches produce giant, sustainable businesses. I don’t think either is right or wrong. They’re just different trade-offs.
Even with all that investment, the Spanner team was afraid to touch their own consensus implementation. Mazières noted that out of 25 Google engineers, maybe one really understood the Paxos layer, and nobody wanted to modify it. They could have optimized by making the logs serve dual use, but it wasn’t worth the risk. This connects back to Raft: consensus is the thing everyone builds on and nobody wants to mess with.
CausalSim
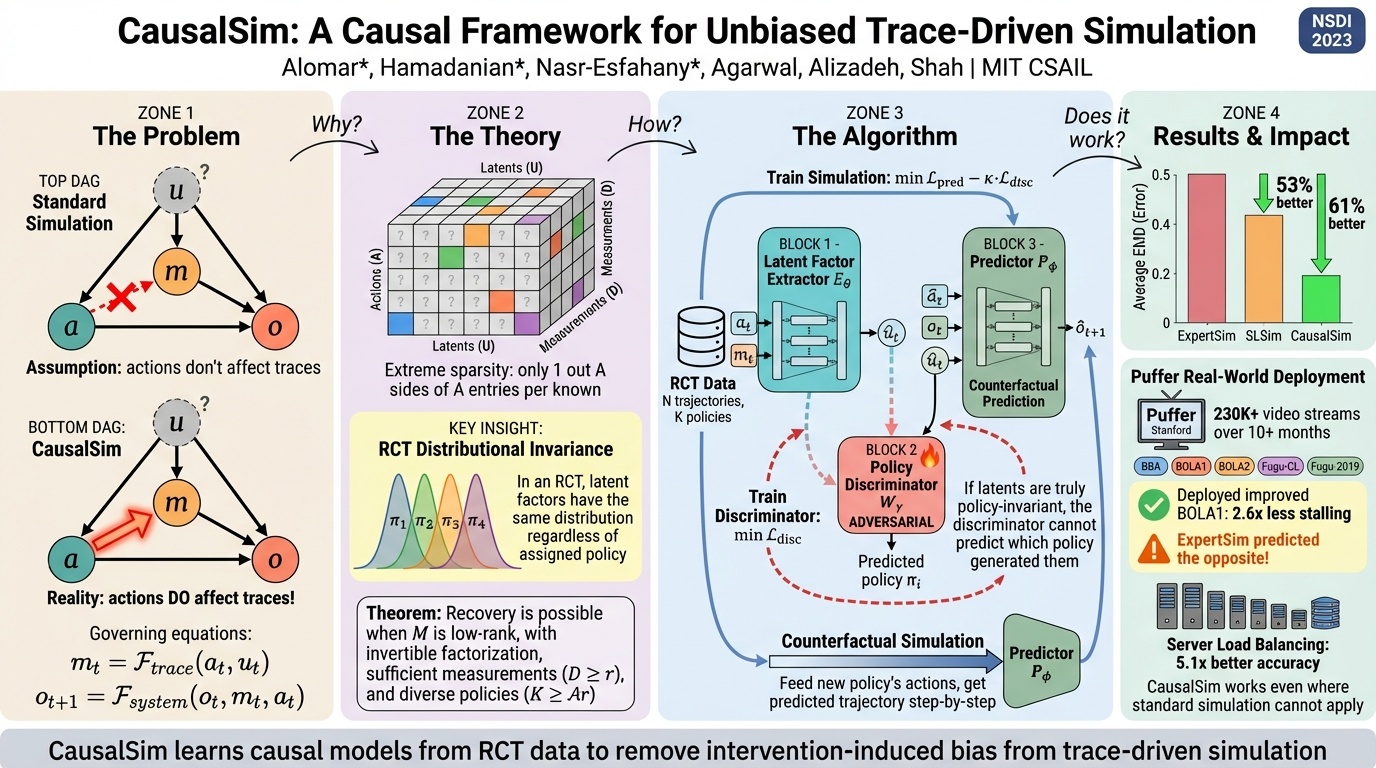
CausalSim tackles a problem anyone doing trace-based product development should care about: when you train on data collected under one policy, can you predict what would have happened under a different one? The data you collected isn’t neutral. It’s contaminated by the decisions that produced it.
This is relevant to my work. A lot of product development depends on traces, and there’s a real question about what it means when the constraints of your traces give the upper limit of performance for an algorithm. CausalSim’s approach, using adversarial debiasing to extract latent state that can’t reveal which policy generated the data, is clever. But I’ve seen this problem solved pragmatically in many different ways at work. Simulation-based approaches with feedback mechanisms are better in principle but harder to build. In practice, people ship what they can.
Winstein was honest about the paper’s limitations. “They made one prediction that turned out to be a success” is not exactly overwhelming evidence. But the direction matters. If you’re building systems that learn from their own operational data, the question of counterfactual reasoning isn’t going away.
What I took from ten weeks
I came into CS244C wanting to bridge a gap. I’m a PM in Azure Infra for IaaS, and the hard problems I run into are distributed computing problems. I couldn’t keep pattern-matching my way through design reviews. I needed to understand why these systems work the way they do.
Some papers changed how I think. The end-to-end argument gave me a framework for where intelligence should live in a system. The tussle paper made me see capacity allocation as a political choice. Raft convinced me that mathematical perfection matters less than people think it does.
Some papers didn’t land at all. I don’t remember VL2 or FaRM. I’m not sure I fully understood Simplex’s connection to erasure coding. That’s fine. Not everything sticks, and being honest about what didn’t is more useful than pretending it all mattered equally.
The most valuable thing wasn’t any single paper. It was watching Winstein and Mazières disagree in real time, admit they didn’t understand things, and treat the material with both deep respect and genuine skepticism. Mazières threw the Paxos paper at the wall. Winstein tried to end his own field and mostly gamified it instead. A colleague of Mazières who co-authored the Spanner paper admitted they might have “made up” a detail for the publication.
I used paper-shepherd, a Claude Code plugin I built for reading academic papers using Keshav’s three-pass method, to work through most of the papers in this series. It helped structure my reading, but the real learning happened in class, listening to two professors who built these systems talk about where the seams are.
Winstein asked the class in the final lecture: “Do you all feel proud of what you accomplished?” A student answered: “Getting there.” Winstein said: “Getting to pride. All right. That’s good.”
Getting to pride. That’s about where I am too.
Part 4 of 4 in “Papers Your Senior Engineers Should Have Read” from CS244C at Stanford, Winter 2026. Part 1 | Part 2 | Part 3