The Math Your Network Engineers Aren't Doing
Congestion control
I expected congestion control to be the boring week. Rate limiting, back-off timers, TCP stuff from undergrad. Winstein reframed it immediately. He said that if you think about all the problems in computer systems, there are questions about what can and cannot happen (security, routing, formal methods), and then there are questions about how much of it everyone gets to do. If you solve that second category in a decentralized, partially observable way, you could call it congestion control. “In some sense it’s like half of all of computer systems.”
I wasn’t sure I bought that claim at first. But the more I think about it, the more it holds up. At Azure, a significant portion of the extra bandwidth we provision is essentially a brute-force answer to congestion. We overprovision because solving it algorithmically is harder than throwing capacity at it.
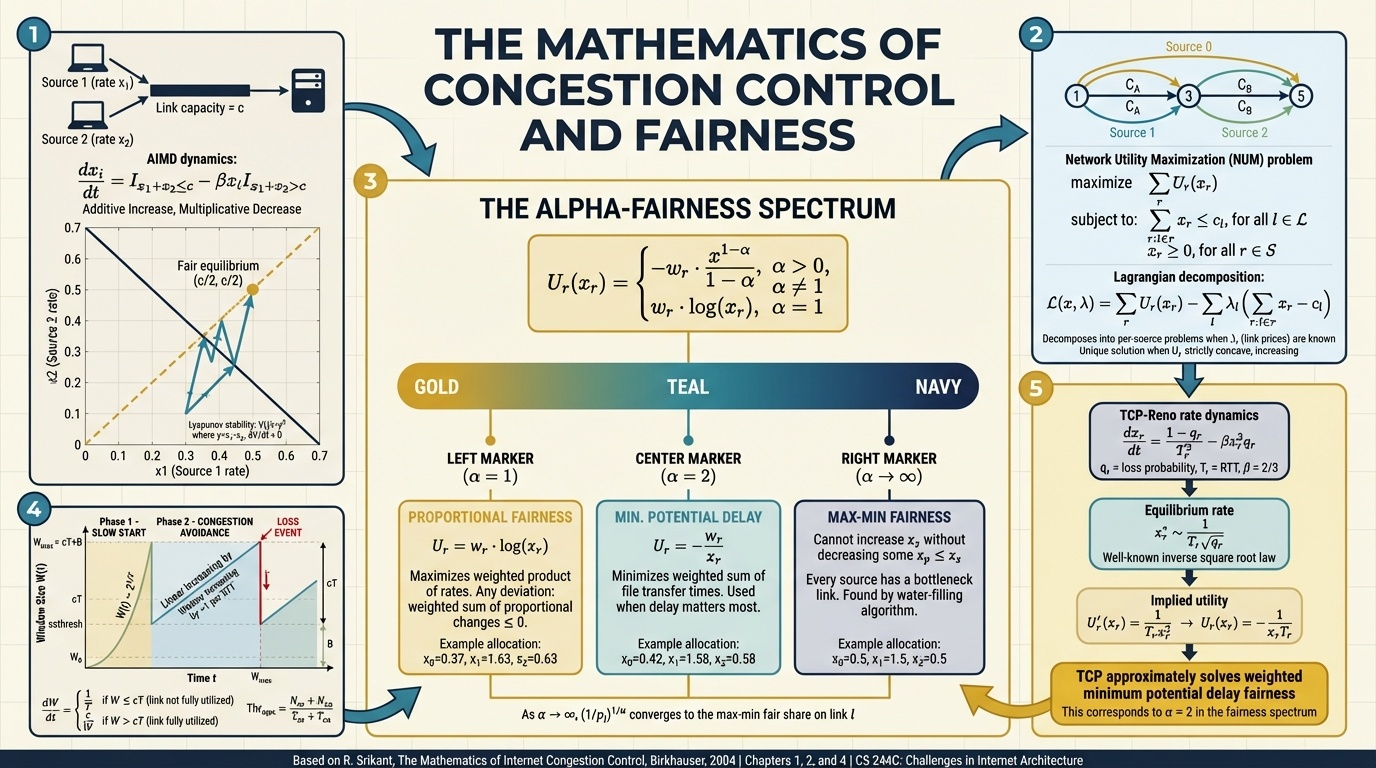
The assigned reading was from Srikant’s textbook on congestion control mathematics. The headline result is striking: there’s a single mathematical equation, parameterized by one variable alpha, that encodes every notion of fairness you could want in a network. Max-min fairness, proportional fairness, minimum delay. They’re all just different values of alpha. Winstein called it “the coolest part of the reading.”
What’s surprising is who figured this out. It wasn’t the systems people at Berkeley who actually built TCP. It was British operations research mathematicians, a full decade later. Frank Kelly and colleagues proved that the AIMD policy Jacobson and Karels shipped in BSD Unix, designed purely to stop congestion collapse, turned out to produce a globally optimal result for a particular fairness notion. Winstein called this teleology: discovering the ends that a means was achieving all along. The Berkeley engineers had no idea they were optimizing anything. They just didn’t want the network to fall over.
Starvation
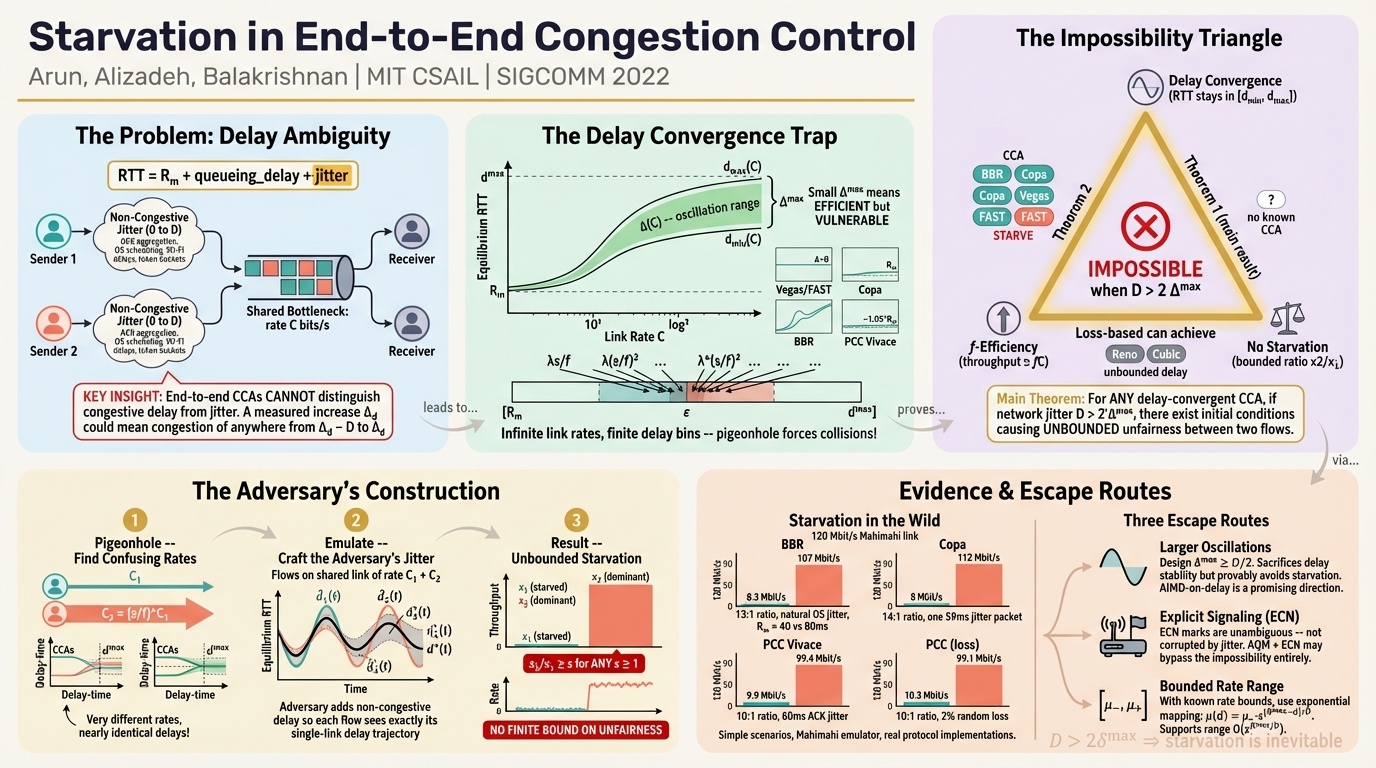
The starvation paper introduces something that sounds obvious but apparently nobody had formalized: what if the network itself is your adversary? Not dropping packets, just delaying them consistently to make you think the link is slower than it actually is. You never observe the true minimum RTT. Under those conditions, no deterministic congestion control scheme can avoid starving some flows.
Winstein was candid about why nobody had considered this before. The instinct is to dismiss it: if the network is your adversary, it could just drop all the packets, so why bother? But the paper’s impossibility result is more subtle than that. The adversary is just delaying packets to match the RTT it showed you initially. A 440 gigabit per second link that fools you into thinking it’s only 40.
The distance between theory and practice in this space is still enormous. These theorems are new, and the practitioners who build real congestion control are still far away from incorporating them. It’s one of those areas where the field is slowly converging from both directions.
Remy
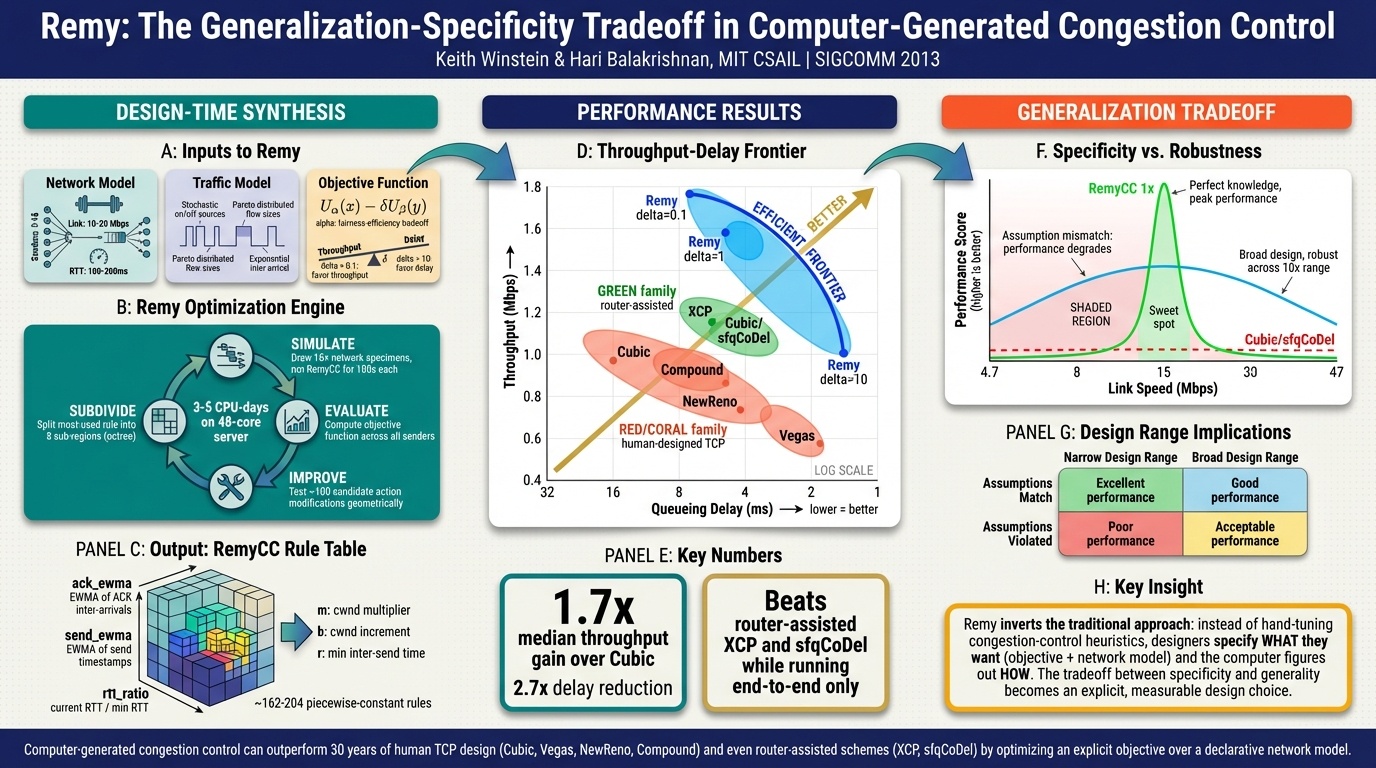
This is the paper Winstein co-authored during his PhD. His stated goal was to end the field of congestion control. If all the human-designed schemes are just points in a solution space, why are humans coming up with them? Let a computer search the space instead.
Remy uses computer search to generate congestion control schemes that outperform human-designed ones within their training distribution. The problem is generalization. An RL-trained agent does phenomenally within the range it trained on and falls apart outside it. Train on a 2x range of link rates and it’s great. Encounter a link rate outside that range and performance craters.
I’ll be honest: I found this paper a little oversimplified. Winstein is one of the professors teaching the course, so there’s an inherent awkwardness in critiquing his own work in his own class. But my reaction is that putting too much intelligence into a highly distributed system is bound to fail. Where do you host these RL agents? What’s the compute cost? What about throttling? These are systems engineering questions that the paper doesn’t really engage with. My sense is that ideas like these stay in academia because they’re too expensive and too fragile for the real world, not because they’re theoretically wrong.
Winstein asked an RL expert about networking problems, and the expert said they’re harder than self-driving cars because they’re so partially observable. That’s probably true. But the practical response at most companies, including mine, is to just overprovision the network rather than try to solve congestion optimally. It’s inelegant but it works.
One thing I kept coming back to during this section is how the datacenter violates the end-to-end argument on purpose. Public internet infrastructure should be dumb, per Saltzer’s argument. But inside a datacenter, you control both ends, so you can make the network as smart as you want. The E2E argument trades off performance for openness and reliability. Datacenters need performance, so they put intelligence back into the network. The E2E argument has a scope, and the datacenter is where that scope ends.
Part 3 of 4 in “Papers Your Senior Engineers Should Have Read” from CS244C at Stanford, Winter 2026. Part 1 | Part 2 | Part 4