Consensus Is Tricky, and People Don't Want to Mess With It
Two-Phase Commit
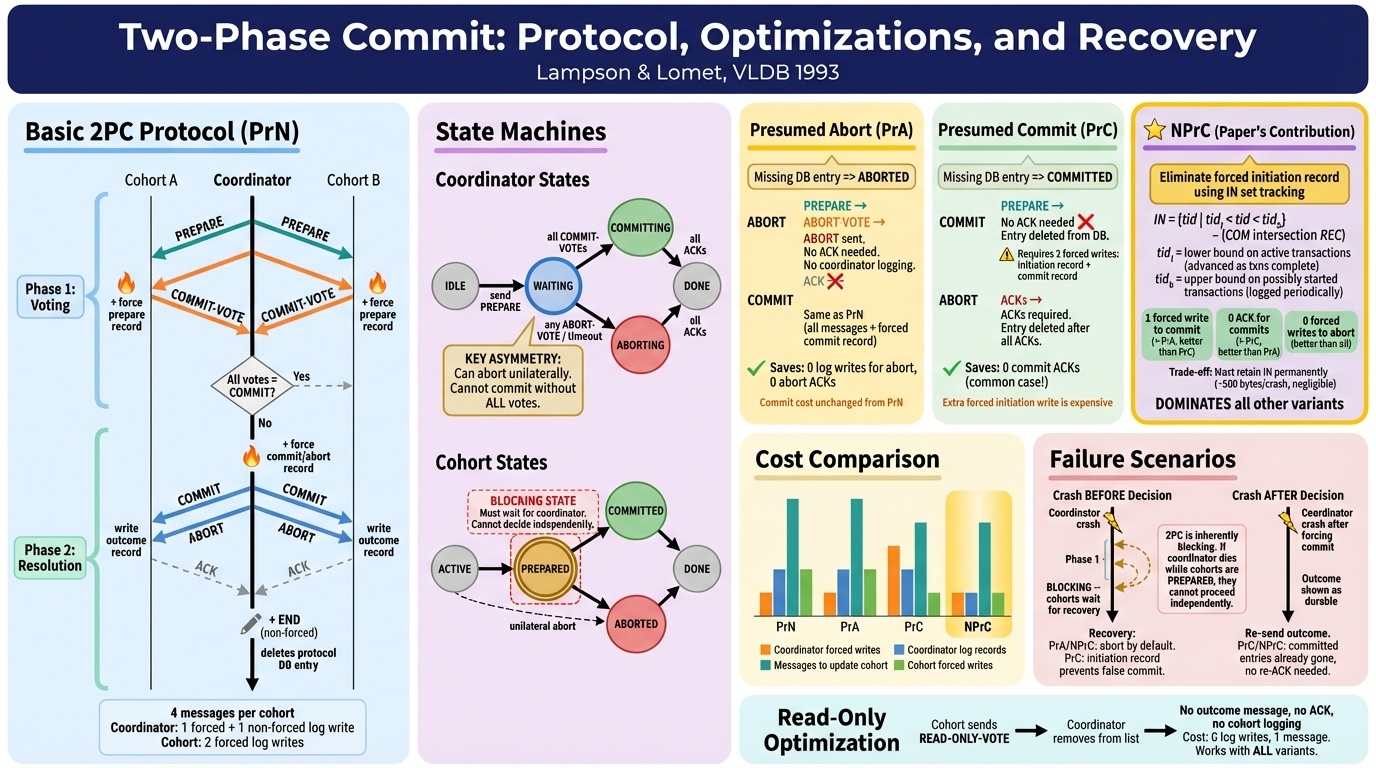
Two-phase commit is how distributed databases agree on whether to commit or abort a transaction. A coordinator asks every participant: can you commit? If everyone says yes, commit. If anyone says no, abort.
The subtlety is in what “yes” means. Mazières explained that when a participant says yes, it’s making a promise: I will not forget about this transaction, I will not release the locks, and if everyone else agrees, I can commit. It’s a binding commitment with no take-backs. But the asymmetry is interesting. The coordinator can always unilaterally abort, it just can’t unilaterally commit. Every optimization in 2PC is trying to shave off disk writes while preserving that asymmetry.
I’ve seen this in production. We’ve had outages where a SQL database goes down and not all nodes are affected, but the quorum requirements from the commit protocol mean the whole thing is unavailable anyway. Participants holding locks, waiting for a coordinator that isn’t coming back. The paper is from 1981, and this failure mode is still exactly as described forty years later.
What I took from this is that 2PC works. It’s been in production for four decades. But it has this fundamental brittleness that everyone who uses it learns to live with rather than solve.
Zookeeper
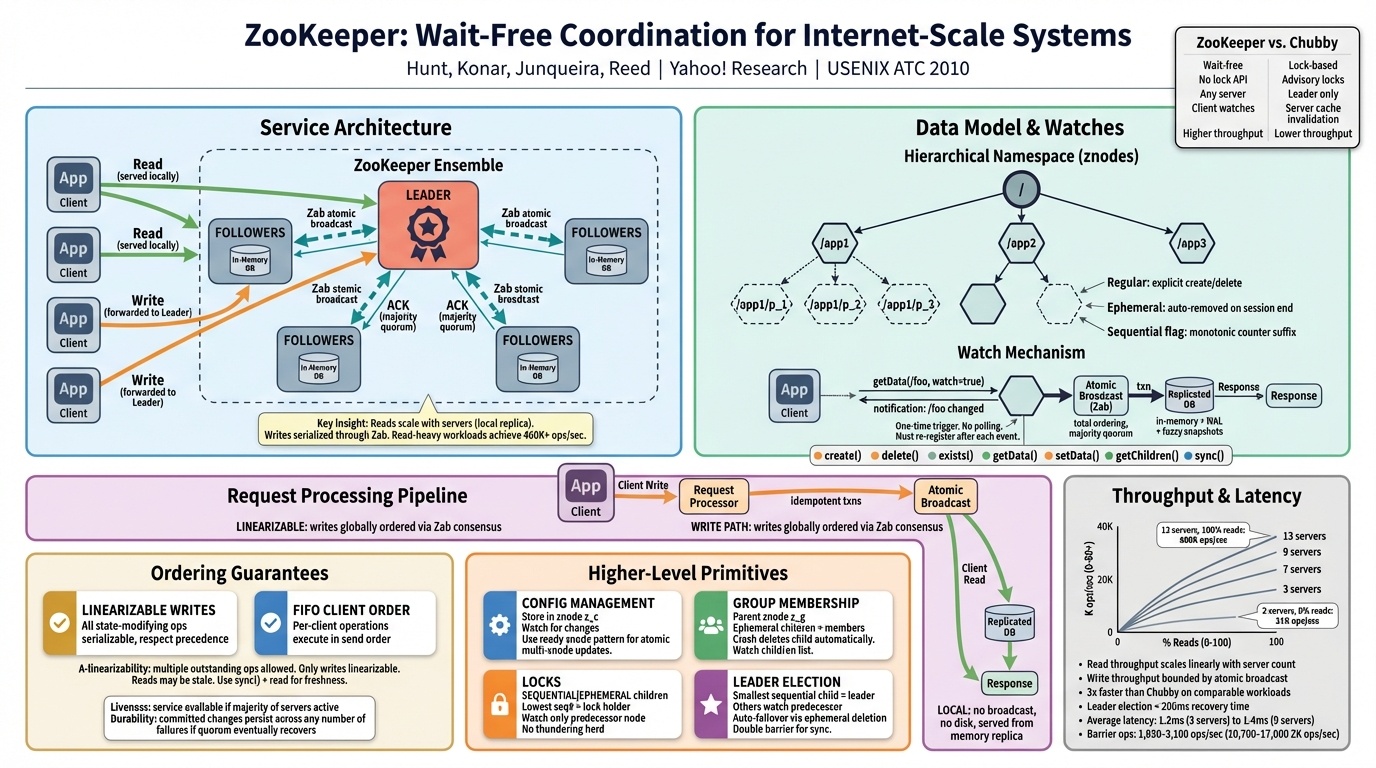
Zookeeper was the paper I enjoyed most in this section, mostly because it felt practical in a way the theory papers didn’t. It came out of Yahoo, and Winstein had fun with the Google rivalry. He described Google’s Chubby as “the dumb solution” and framed Yahoo’s approach as a quiet flex: where Google used locks, Yahoo said we don’t need them. Zookeeper provides wait-free primitives, which are strictly more powerful. You can build locks on top if you want them, but the service itself never makes a client wait.
The catch is that you still have to assemble the building blocks correctly. Winstein walked through the thundering herd problem: a thousand threads watching an ephemeral file, one wins and the file is deleted, and all 999 others wake up simultaneously trying to create it again. Only one will win. The rest wasted a round trip for nothing.
I liked this paper because it felt like the kind of engineering I see at work. You get the right primitives, and then the hard part is using them correctly at scale. Consensus lives underneath, and most users never think about it, which is both the point and the risk.
Raft
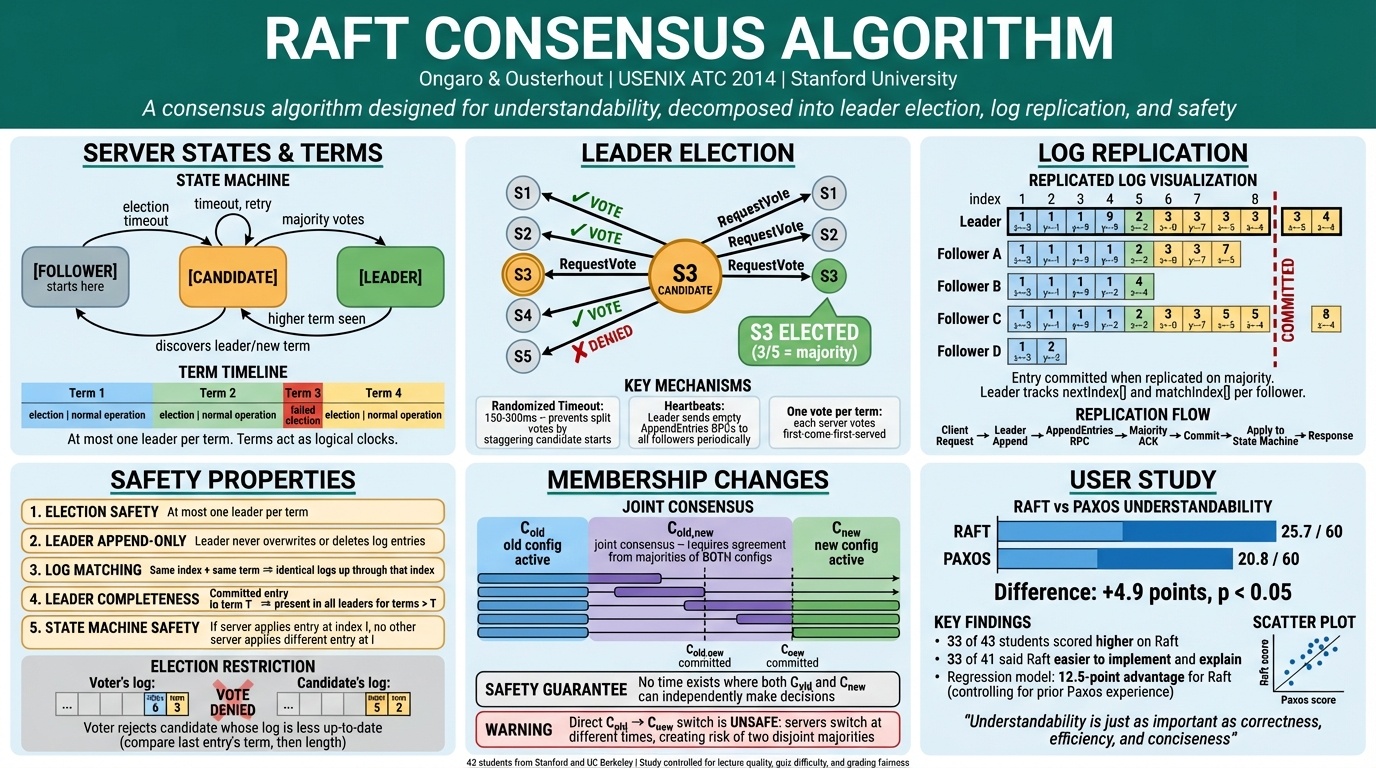
Raft’s research contribution was understandability. That’s it. Mazières was blunt about why it needed to exist. The original Paxos paper, he said, is “literally unreadable.” Lamport tried to be cute with a story about a Greek island, and the result is thirty pages of inside jokes that make you throw the paper at the wall. The actual protocol is two rounds of messages.
Then Mazières confessed something that stuck with me. The first time he taught distributed systems at Stanford, he wrote a paper called “Paxos Made Practical” where he explained Paxos in the first paragraph and then gave a detailed explanation of a completely different protocol, viewstamp replication, without realizing they were essentially the same thing. A Stanford professor who builds cryptographic protocols for a living mixed up two consensus algorithms in his own course notes.
And Raft, the protocol designed specifically to be understandable, still had a correctness bug that Mazières found in an earlier draft.
My honest reaction to all of this is that mathematical perfection matters less than people in academia think it does. These bugs have been in production for a long time. Systems built on imperfect consensus handle trillions of requests a day. You build solid systems with defense in depth, covering most failure modes, not all of them. Provable correctness is a nice-to-have, not a prerequisite for shipping.
Simplex
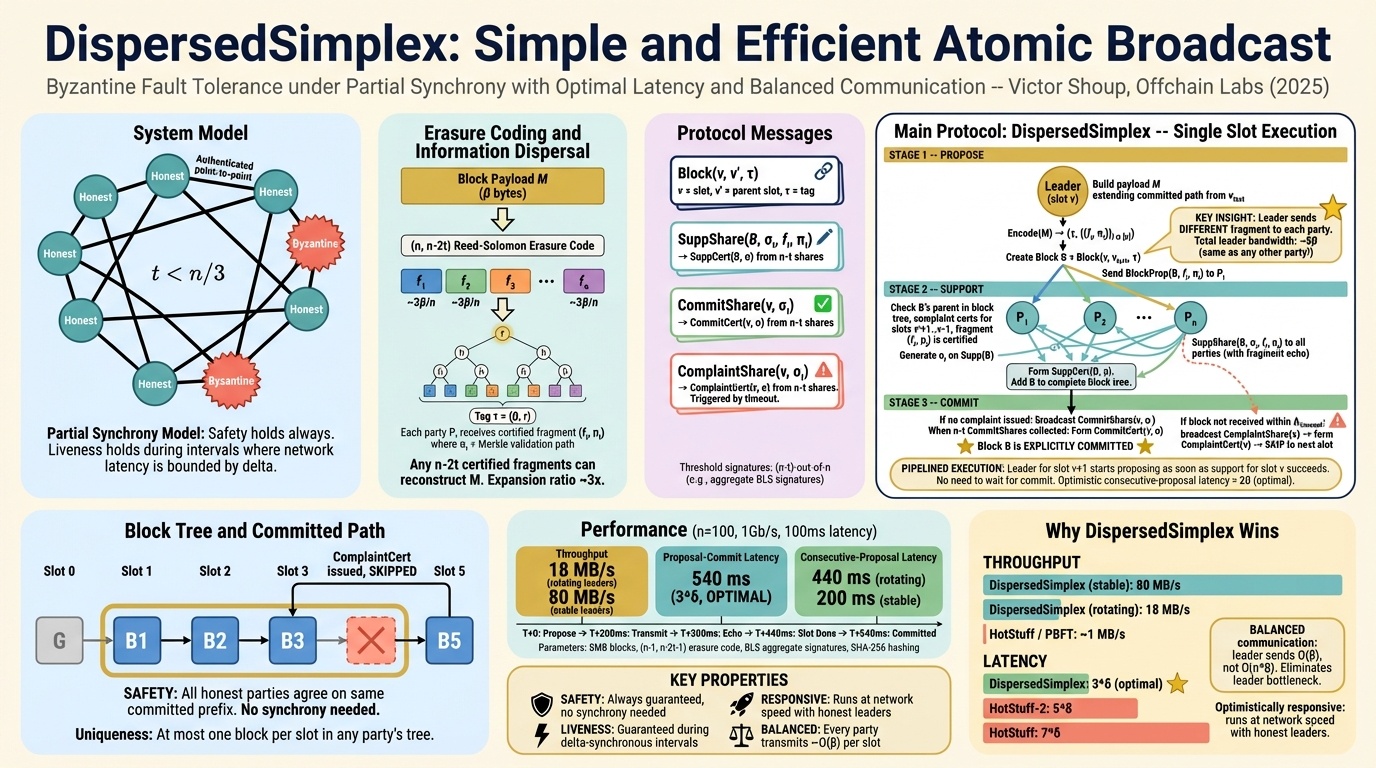
Simplex extends consensus to settings where nodes might lie. Everything before this assumed fail-stop failures, where a crashed node just stops talking. Byzantine fault tolerance asks: what if a faulty node starts actively sending different messages to different people?
The jump isn’t incremental. You go from needing 2f+1 nodes to tolerate f crash failures, to needing 3f+1 nodes for f Byzantine faults. Every two quorums need to overlap at at least one honest node.
Mazières offered a framing I found genuinely clarifying. Voting, he said, is really just a bad consensus protocol that can get stuck. You ask a question and you might get a definitive answer, or you might get “maybe.” Simplex’s insight is that if your first vote might get stuck, you vote on whether the first vote succeeded. Two questions, each rescuing the other from permanent indecision.
This paper connected to something practical for me around erasure coding and how it can be used to increase scale, though I’d have to go back and look up the specific connection. When a student asked whether BFT has applications outside blockchain, Mazières was honest: it was a niche research area until blockchains came along.
Part 2 of 4 in “Papers Your Senior Engineers Should Have Read” from CS244C at Stanford, Winter 2026. Part 1 | Part 3 | Part 4