From Copy-Paste to Claude Code: How I Rebuilt My Podcast Summarizer and Learned to Actually Use AI
A story about over-engineering, production failures, and what happens when you let multiple AI models review each other’s architecture.
Chapter 1: The Problem
I love podcasts. Lex Fridman, Acquired, Huberman, The All-In Podcast, dozens more. They represent a firehose of knowledge that I genuinely want to absorb — interviews with experts, deep dives into history, technical breakdowns of everything from neuroscience to startup strategy.
But I have a kid now. And a job. And sleep, sometimes.
The math stopped working sometime in early 2025. I subscribed to more podcasts than I could ever listen to. There are literally fewer hours left in my life than podcast episodes in my backlog. That realization hit differently.
So I had an idea: what if I could distill the core knowledge from every new episode and get it delivered to my inbox? Not a transcript — those are useless walls of text. A real summary. The key arguments, the surprising insights, the actionable takeaways. Something I could read in five minutes over coffee instead of committing 90 minutes to an episode that might not even be relevant.
This felt like the perfect AI project. I was already trying to ramp up my use of AI tools for coding, and building something I would actually use every day seemed like the ideal forcing function. I could learn how to build with AI while building something for myself.
What followed was a year-long journey that taught me more about software engineering — and about how to work with AI — than any course or tutorial ever could.
Chapter 2: V1 — The Naive Builder
I started the first version in March 2025. My development environment was two browser tabs: one with Claude, one with ChatGPT. I would describe what I wanted, get code snippets back, paste them into VS Code, and iterate.
This worked. Sort of.
The problem with browser-based AI coding is that neither model could see my full codebase. I would describe my project structure in natural language, paste relevant files into the chat, get suggestions back, and manually integrate them. Every conversation started from scratch. Context was something I had to rebuild every time I opened a new chat window.
I moved to VS Code with GitHub Copilot after a few weeks. That helped with autocomplete, but the core workflow was still the same: me as the bottleneck, translating between what the AI suggested and what my codebase actually needed.
The “Every Best Practice” Trap
Here’s what happens when you’re learning to code with AI and you’re eager to do things right: you ask the AI for best practices, and it gives you all of them.
My podcast summarizer needed one thing: take an audio file, transcribe it, summarize it, email the result. Instead, I built a system with:
Four different summarization engines. LangChain with a LangGraph state machine for map-reduce summarization. LlamaIndex for alternative summarization. A Spacy + Transformers neural pipeline (514 lines of code). An “ensemble summarizer” that combined multiple methods. I used LangChain. The other three sat there, imported but never called, adding weight to my dependency tree.
Four download strategies. Requests, wget, youtube-dl, and Playwright (a headless browser). Each tried in sequence as a fallback chain. For downloading podcast audio files. From RSS feeds that had been serving MP3s reliably since 2004.
Two separate API services. A FastAPI backend and a completely separate Flask frontend, connected by Azure Service Bus message queue. For a personal project with one user: me.
50 Python dependencies. PyTorch (for a summarizer I never used). Playwright (for a downloader I never needed). crawl4ai (a web scraper, just in case). cloudscraper (for anti-bot bypass on… podcast RSS feeds).
The database layer alone told the story. My summaries.py file — a single file managing summary operations against Supabase — was 5,739 lines long. The episodes manager was 3,946 lines. The transcription manager was 4,048 lines. These weren’t complex algorithms. They were CRUD operations wrapped in layer after layer of abstraction.
I had 80 Python files, roughly 10,000 lines of code, and 30+ environment variables. The architecture diagram looked like something from a mid-size company’s backend, not a personal podcast tool.
But look at the frontend. It was polished. Purple gradients, feature cards, a “Trusted by Podcast Enthusiasts” section with social proof, a bottom CTA with “Start Your Free Trial.” I built a marketing site for a product with one user.
And here’s the thing: it worked. The emails arrived. The summaries were good. I used it every day from April through November 2025.
Log in, and the app looks like a real product. A library of subscribed podcasts with cover art, a discover page for browsing, a settings page with email frequency controls, summary detail levels, even custom AI instructions:
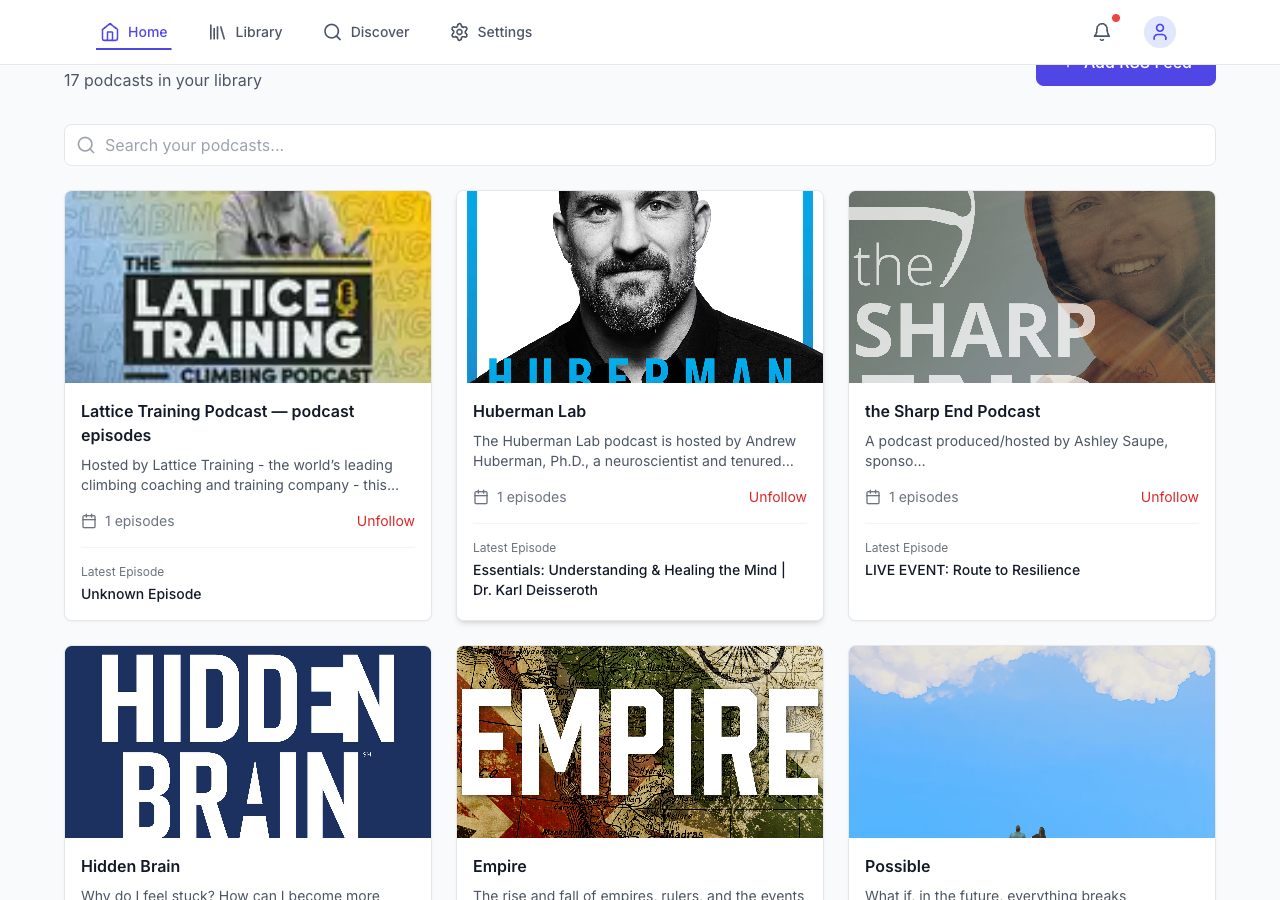
The discover page was a browsing grid of available podcasts across categories. It looked like a polished consumer product:
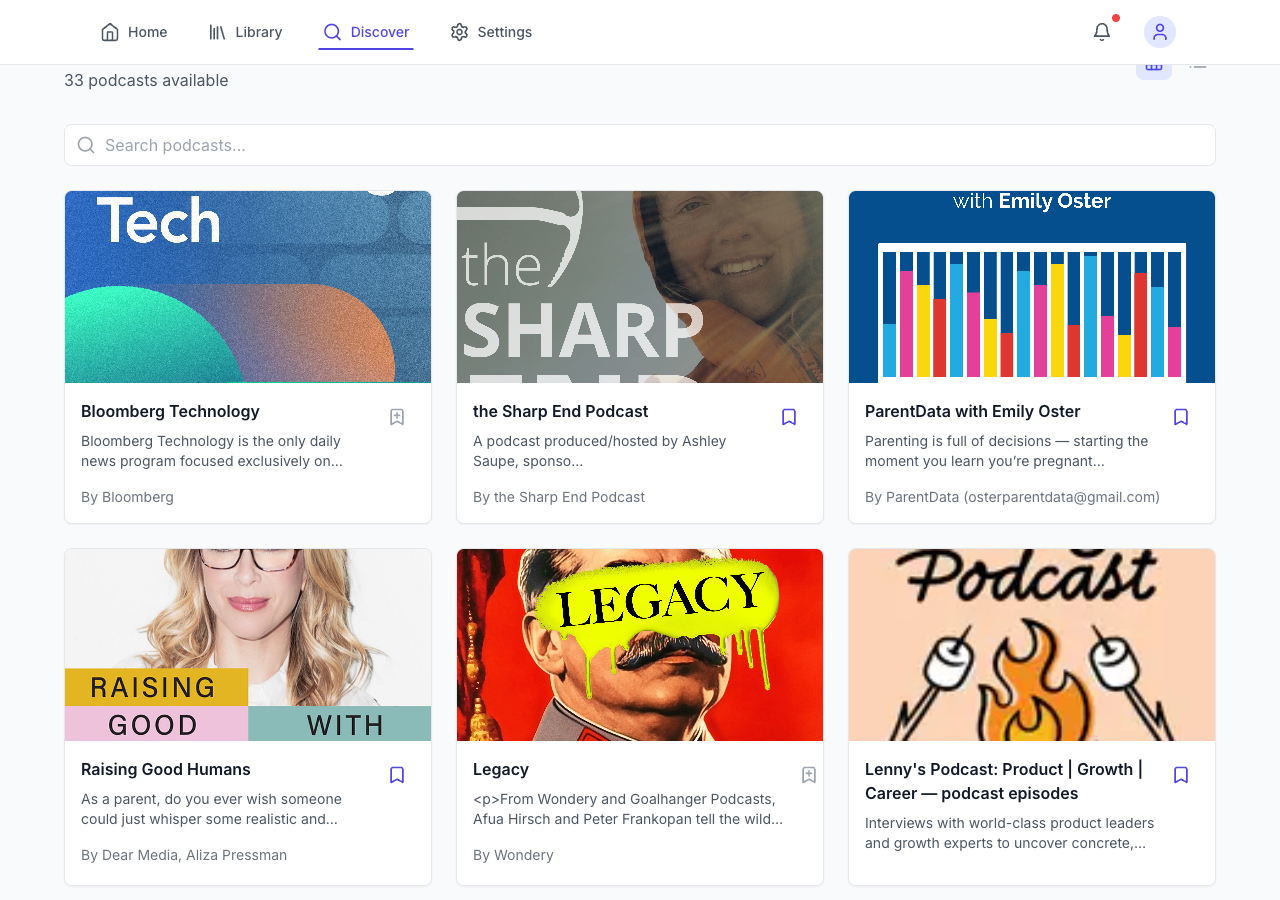
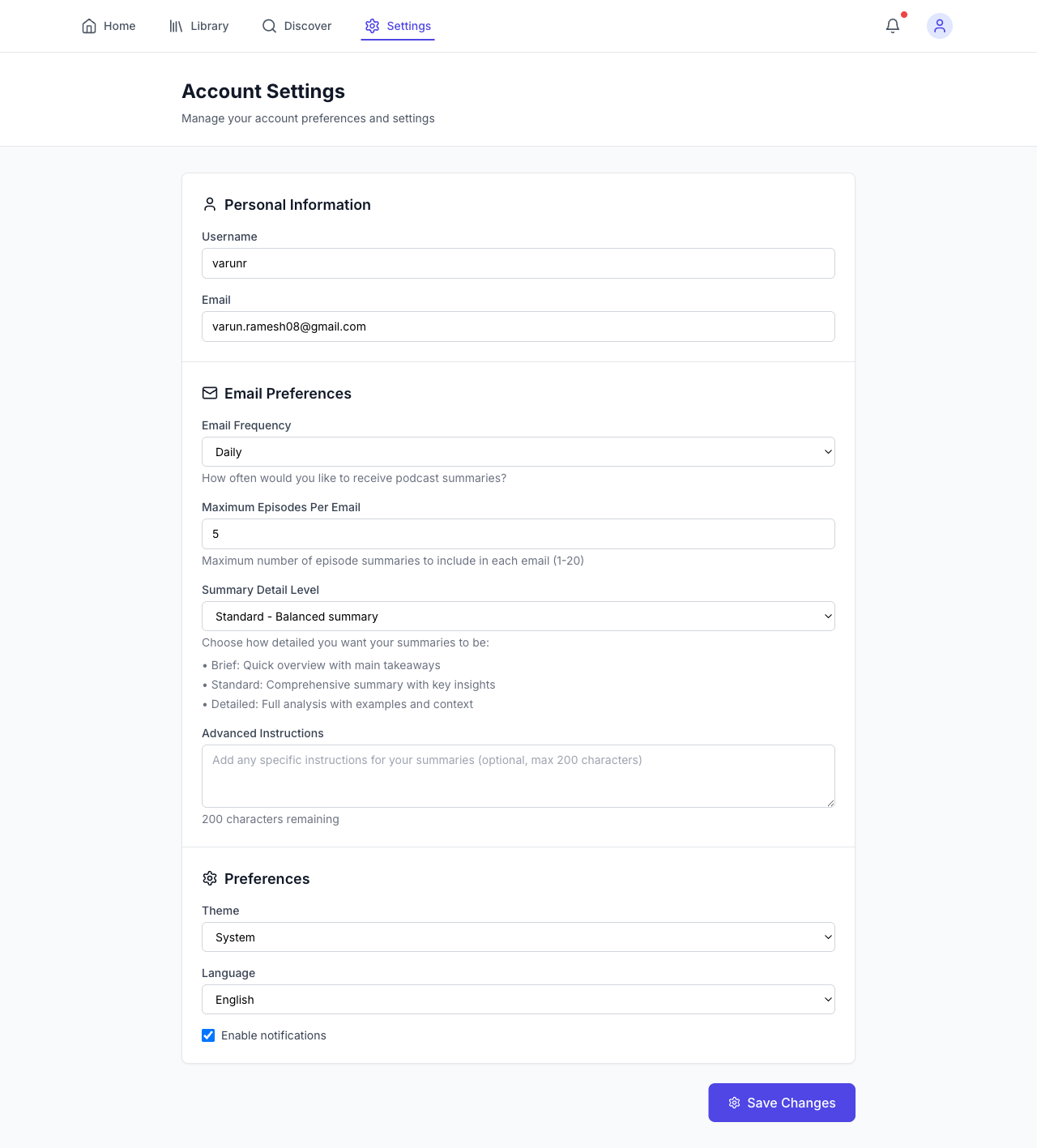
All of this was built for one user. Me. The settings page had options for email frequency, summary detail level, custom AI instructions, theme preferences, language selection, and notification toggles. These are features a product team would build for thousands of users. I built them because the AI suggested them and I didn’t have the experience to say no.
But every time I wanted to change something — add a new podcast, adjust the summary format, fix a bug — I had to spelunk through a codebase that I, the sole author, barely understood.
That’s the signature of naive AI-assisted development: functional but incomprehensible. The AI generated sophisticated code in response to sophisticated questions. I kept asking “what’s the best way to do X?” and the AI kept answering with enterprise-grade solutions for a side project.
Chapter 3: The Gap
V1’s last meaningful code commit was May 2025. After that, just a cleanup in July where I removed accidentally committed secrets (another sign of the chaos) and added a README.
For seven months, the service ran on autopilot. It worked well enough that I didn’t touch it. But “works” and “maintainable” are different things, and I knew that any significant change would require me to re-learn my own codebase.
During those seven months, two things changed.
First, I discovered Claude Code — Anthropic’s CLI tool that works directly in the terminal. Unlike browser-based AI or VS Code extensions, Claude Code could see my entire codebase, run commands, read files, and maintain context across a development session. It wasn’t just autocomplete or chat. It was a collaborator that understood the full picture.
Second, I started reading about distributed systems design. Not the academic papers — the practical wisdom from engineers who had built things at scale and then simplified them. The recurring theme was clear: for distributed systems, simpler is better. Every additional component is a failure mode. Every abstraction is a thing that can break. The best architecture is the one with the fewest moving parts that still solves the problem.
This hit me hard because my v1 podcast summarizer was a distributed system — Azure Service Bus connecting two APIs, background jobs processing queues, Supabase as a remote database — and I had made it as complicated as I could possibly make it. I hadn’t earned that complexity. I didn’t have the traffic, the team, or the operational maturity to justify it.
In December 2025, I decided to start fresh. Not refactor. Rewrite.
Chapter 4: V2 — The Informed Builder
V2 started on December 18, 2025. Not with code. With a design document.
This was the first major difference from v1. Instead of opening a browser and asking “how do I build a podcast summarizer?”, I sat down with Claude Code and brainstormed. What are the actual requirements? What are the constraints? What does “good enough” look like?
The design document was 219 lines. It stated three goals:
- Keep the system cheap, reliable, and easy to maintain.
- Prefer batching and scale-to-zero over low latency.
- Support YouTube and Podcasts.
And critically, it listed non-goals: no multi-language support, no real-time delivery, no complex analytics. Every feature I might be tempted to add later was explicitly called out as “not now.”
Philosophy Shifts
V2’s design philosophy was the opposite of v1 in almost every way:
| Decision | V1 | V2 |
|---|---|---|
| Summarization | 4 engines (1 used) | 1 LLM, 1 prompt |
| Database | Supabase + 8 manager classes | Azure SQL + SQLAlchemy ORM |
| Download | 4 fallback strategies | yt-dlp or HTTP GET |
| APIs | FastAPI + Flask + Service Bus | FastAPI only |
| Summaries | Per-user variants | Episode-level, shared |
| Dependencies | 50 packages | ~20 packages |
| Design docs | 0 | 47 |
| Tests | Manual integration tests | 86 test files, 22K LOC |
The last two rows matter most. V1 had zero design documents and relied on manual testing. V2 produced 47 design documents in five weeks and had more test code than production code (22K vs 15K lines).
And then look at the product. Compare v1’s marketing-heavy landing page to v2:
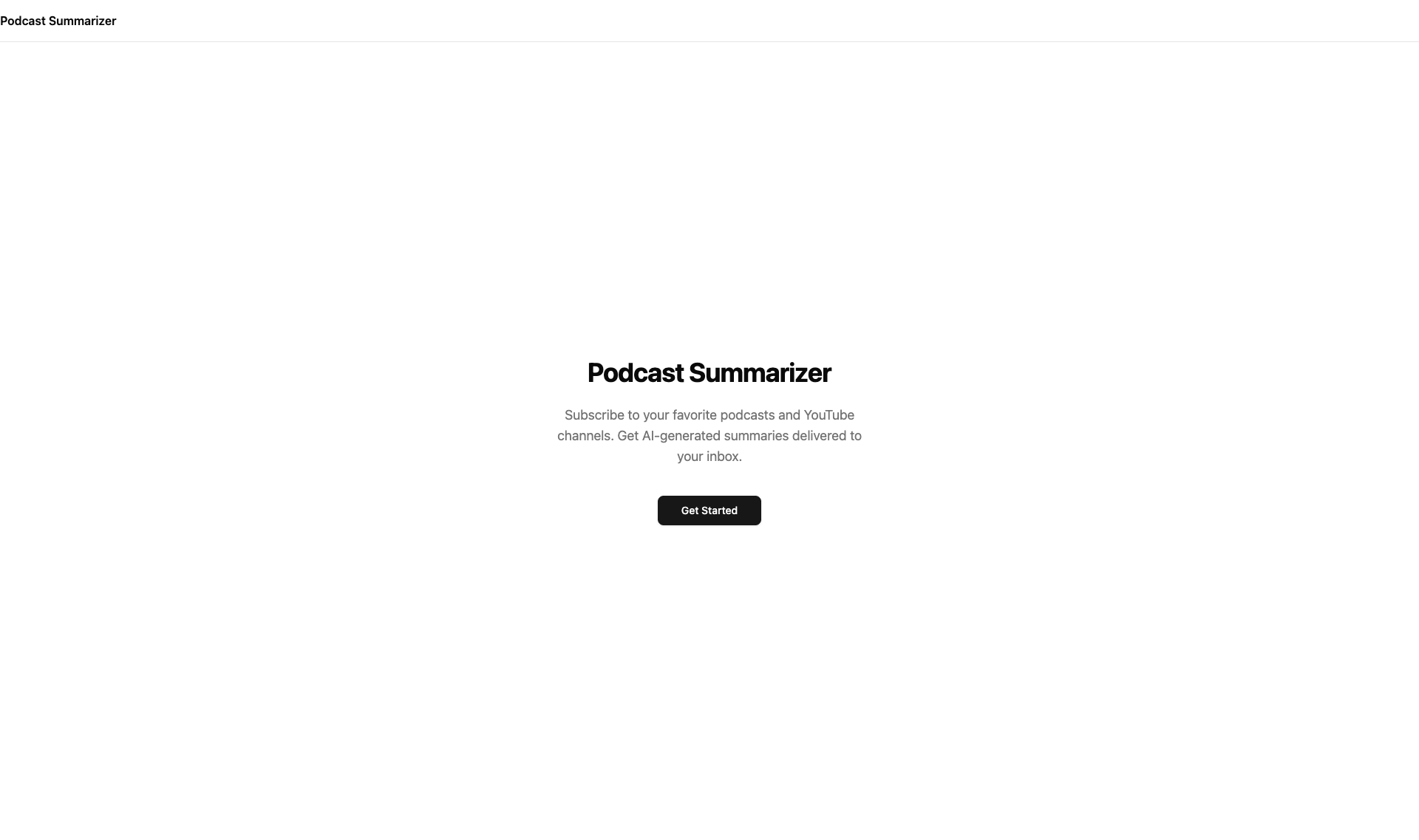
One heading. One sentence. One button. No feature cards, no social proof, no purple gradients. The design reflects the philosophy: do one thing well.
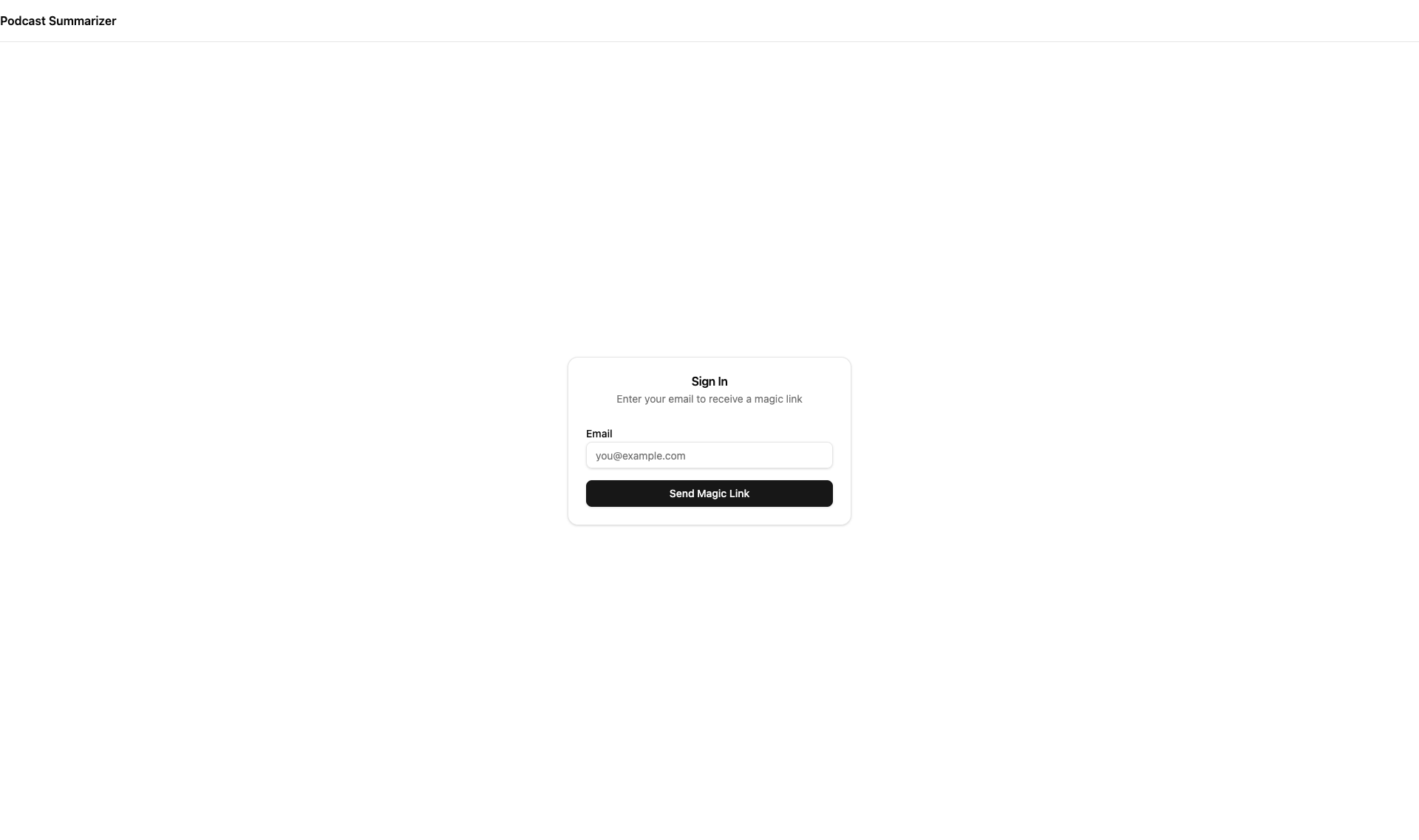
Click “Get Started” and you get a magic link auth flow — no passwords, no social logins, no account creation friction:
Once authenticated, the nav reveals the actual app: Channels, Subscriptions, Account, and (for me) Admin. The channels page is a clean list — each channel shows its name, description, type (podcast or YouTube), episode count, last update, and a single Subscribe/Subscribed toggle:
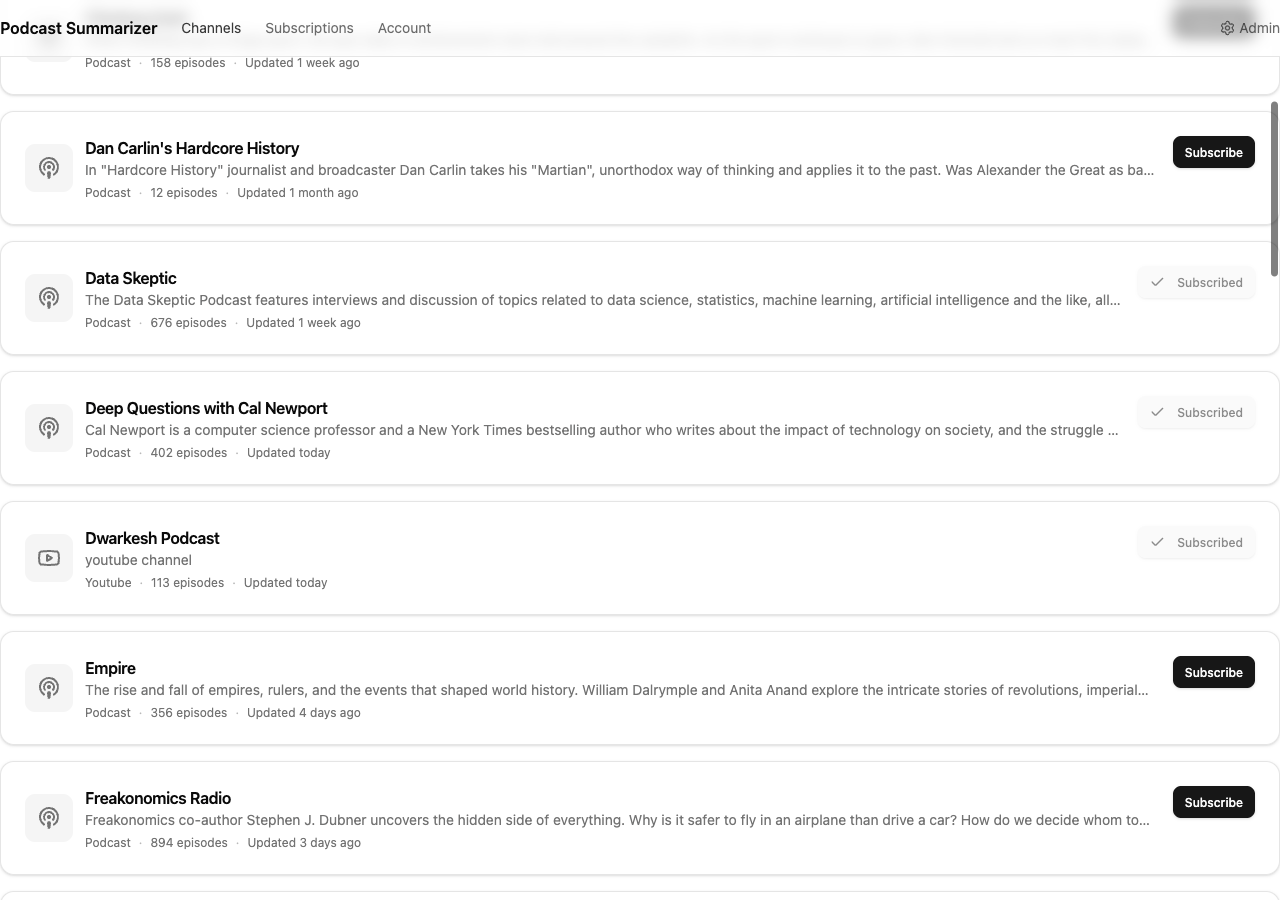
Compare this to v1’s grid of podcast cover art. V2 doesn’t even show images. It shows data: how many episodes, when it was last updated, whether you’re subscribed. The information hierarchy reflects what actually matters when managing subscriptions.
And then there’s the admin dashboard — something v1 never had:
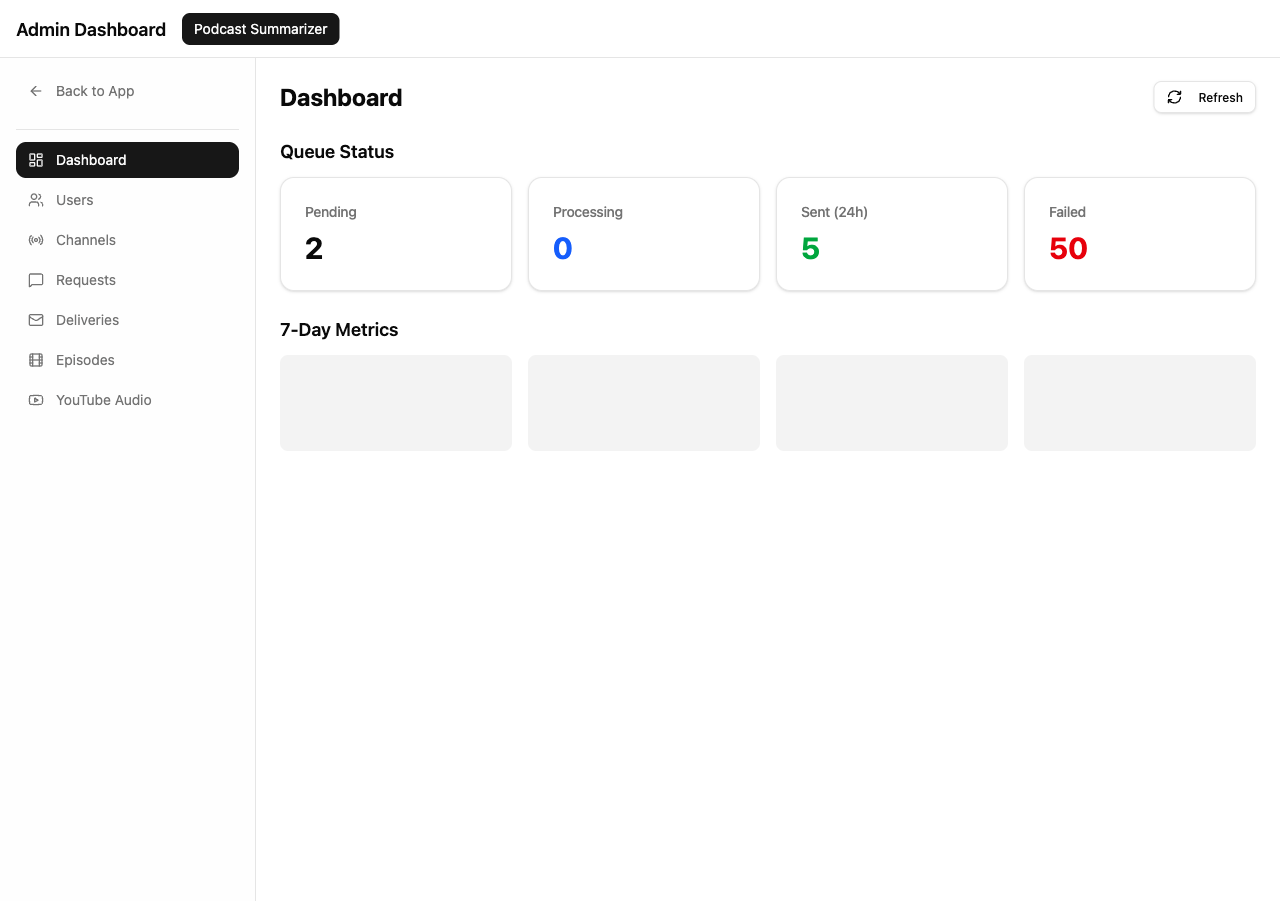
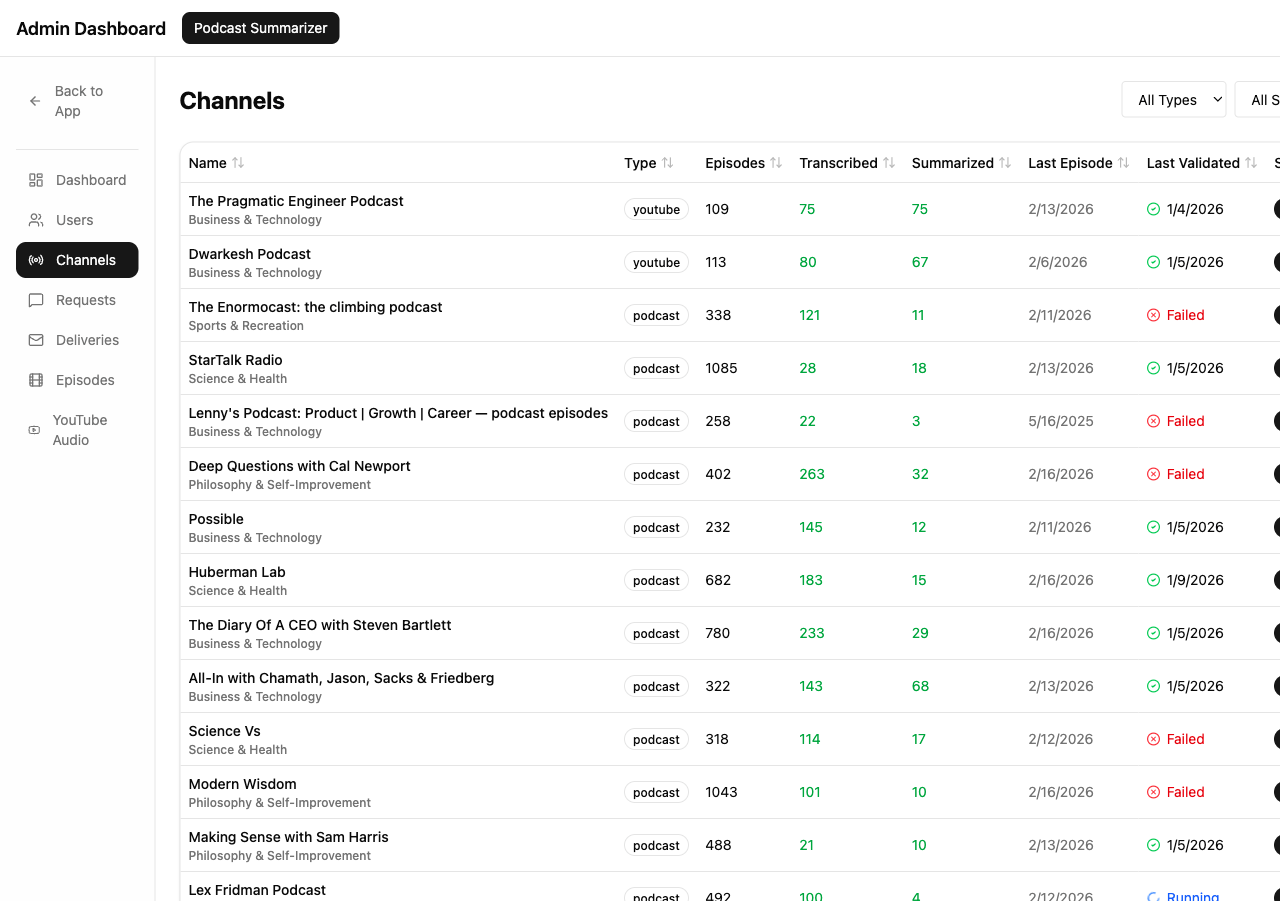
The admin view shows something v1 completely lacked: operational awareness. I can see exactly how many episodes each channel has, how many have been transcribed, how many summarized, when the last validation ran, and whether anything is failing. The Deliveries page shows the email queue. The Episodes page lets me search by title. The YouTube Audio page tracks download status.
V1 had a prettier UI. V2 has a functional one.
The Claude Code Difference
Claude Code changed the velocity equation fundamentally. With v1, I could write maybe 2-3 meaningful commits per day, spending most of my time as a human middleware layer between the AI and the codebase. With v2, the commit log tells a different story.
290 commits in 5 weeks. An average of 8 per day. On Christmas Day alone, I pushed 51 commits. The next day, 27 more. That’s 78 commits in 48 hours — not because I was typing faster, but because Claude Code could implement full features end-to-end while I focused on design decisions and code review.
The workflow was: brainstorm the design together, write a design document, review it, then tell Claude Code to implement it. Each feature started as a conversation about what we were building and why, then became a spec, then became code. The AI wasn’t generating snippets I had to integrate. It was implementing complete features against a shared understanding of the architecture.
This is the difference between using AI as a search engine and using AI as a collaborator. The browser-based workflow of v1 was fundamentally a search pattern: “how do I do X?” Copy, paste, adapt. Claude Code’s workflow was collaborative: “here’s the codebase, here’s the design, build this feature.”
Chapter 5: Platform Evolution — Supabase to Azure
V1’s infrastructure was a patchwork. Supabase for the database (PostgreSQL managed via their REST API). Azure Service Bus for message queuing. Azure Blob Storage for files. Azure Communication Services for email. Azure Cognitive Services for Whisper transcription. Multiple cloud providers, multiple authentication mechanisms, multiple failure modes.
V2 consolidated everything onto Azure:
- Azure SQL Database (serverless) — auto-pauses when idle, wakes on connection. Roughly $5-15/month.
- Azure Blob Storage — transcripts, summaries, audio staging with automatic 7-day cleanup.
- Azure Container Apps — serverless containers that scale to zero. One API service (always on), four scheduled jobs (scale to zero between runs).
- Azure Communication Services Email — $0.00025 per email. Negligible cost.
- Azure AI Foundry — GPT-5.2 for summarization. ~$40/month at 100 episodes.
Total monthly cost: roughly $50-80. For a service that processes 100+ podcast episodes per month and emails me summaries of every one.
The consolidation wasn’t just about cost. It was about cognitive load. V1 required me to understand Supabase’s Postgrest API, Azure Service Bus’s message model, and the interactions between multiple authentication systems. V2 had one platform, one authentication model (Managed Identity), and one deployment pipeline.
Infrastructure as Code made this real. V2’s entire infrastructure — every database, every container, every secret, every permission — is defined in a single Bicep file (main.bicep, about 32KB). Push to main, GitHub Actions deploys everything. No clicking through portals, no manual configuration drift, no “works on my machine.”
This was another lesson in simplicity. Consolidating onto one platform eliminated an entire category of bugs: the “it works in Supabase but fails in Azure” kind. When everything speaks the same authentication language and lives in the same resource group, debugging becomes straightforward.
Chapter 6: The Crisis
On January 5, 2026, my podcast summarizer broke spectacularly.
I had added a validation feature — the ability to test a podcast channel end-to-end before approving it for regular processing. You trigger a validation, the system discovers the latest episode, transcribes it, summarizes it, and emails the result. A sanity check.
The problem: each validation triggered a new batch processing job. One validation, one job. Five validations, five jobs. All competing for the same database connection pool.
The error signature told the whole story:
QueuePool limit of size 5 overflow 10 reached24 validation jobs failed. 5 jobs got stuck in “running” state and stayed there for over three hours. The entire system froze. Not just validations — regular podcast processing stopped too, because the connection pool was exhausted.
Here’s what made this painful: I had designed v2 to be simple. The design documents were thorough. The architecture was clean. But I had one bad pattern — trigger_batch_processor_immediate(), which spawned a new Container Apps job for every validation request — and that single function brought down the whole system.
The diagram of the anti-pattern was embarrassing in its simplicity:
N validations → N triggers → N batch jobs → N×(DB connections) → Pool exhaustedI had spent weeks designing a system to avoid the complexity of v1, and then introduced a different kind of failure: the kind that only appears under concurrent load. My test suite passed. My design documents looked clean. But the first time someone (me) clicked “validate” on five channels in quick succession, everything fell apart.
This is the lesson v2 taught me that v1 never could: simple architectures still break. They just break in understandable ways. I could diagnose the January 5 failure in minutes because the codebase was clean enough to trace. In v1, a failure like this would have sent me on a multi-day debugging safari through 80 files and 50 dependencies.
Chapter 7: Phone-a-Friend
After the January 5 failure, I needed to redesign the validation service. But I didn’t trust myself to get it right alone. I had already proven that even careful design could miss critical concurrency bugs.
This is where something unusual happened. Claude Code has a feature I had been experimenting with called “phone-a-friend” — the ability to send a design document to a different AI model for review. Instead of relying on a single model’s perspective, you get a second opinion from a model with different training, different strengths, different blind spots.
I sent my redesign draft to GPT-5.2 Codex, OpenAI’s reasoning model, set to “high” reasoning effort. At 2:30 AM on January 6.
Review 1: The Foundation
The first review focused on fundamentals. Codex recommended:
-
DB lease instead of Azure SDK check. I had planned to check if a job was running by querying the Azure Container Apps API. Codex pointed out this was unreliable — the API can lag, job states can stick in “Running” when the process has died. A database lease (atomic UPDATE with WHERE clause) is self-healing and reliable.
-
Remove immediate triggers entirely. My design still had validation bypassing the regular queue. Codex said: validation should only enqueue with a priority flag. The controller remains the sole trigger. This eliminated the “N validations = N triggers” pattern completely.
-
Heartbeat + TTL for zombie detection. Without heartbeats, a crashed processor holds its work forever. With a 30-minute lease that refreshes every 5 minutes, a dead processor’s work gets automatically reclaimed.
I accepted these recommendations and revised the design.
Review 2: The Race Conditions
At 4:15 AM, I sent the revised design back. This time, Codex found deeper problems:
Trigger race condition (TOCTOU). My design checked if the orchestrator was running, then triggered it if idle. Two API calls at the same time could both see “idle” and spawn two orchestrators. The fix: a single atomic Compare-And-Swap (CAS) using a database key called orchestrator:wakeup. Only one caller can win the CAS. Everyone else gets “already triggered.”
Per-delivery lease with heartbeats. Without this, a stuck delivery blocks forever. With it, the sweeper can reclaim work after the lease expires.
Anti-starvation quota. My LIFO (newest-first) queue could starve old deliveries under sustained load. Codex recommended reserving 2 slots per batch for the oldest pending deliveries. Not because this would happen often, but because it was a cheap insurance policy.
I revised again.
Review 3: The Critical Bug
At 2:30 PM, I sent Rev 3 to Codex again — this time on “xhigh” reasoning effort. The extra compute found bugs that the previous reviews had missed:
CRITICAL: Owner ID handoff broken. The orchestrator was setting processing_owner_id when claiming deliveries, but CPU processors were querying with their own owner IDs. The CPU workers would see zero rows because they weren’t the owner. The entire downstream pipeline was silently broken.
CRITICAL: Premature attempt increment. Deliveries were being moved to “processing” and attempts incremented before transcripts existed. If the GPU transcriber was still working, the sweeper could time out the delivery and mark it as failed — even though transcription was proceeding normally.
The fix was an architectural change: the orchestrator became a router only. It checks for work and triggers jobs, but it never claims deliveries. The GPU transcriber claims its own work, increments attempts. The CPU processor claims deliveries that have transcripts ready. No handoff. No owner ID mismatch. No premature state transitions.
This was the kind of bug that would have made it to production. My tests wouldn’t have caught it because they didn’t simulate the full multi-job pipeline. The design document looked correct on paper. Only a careful line-by-line review by a model with enhanced reasoning capabilities found it.
The Pattern
Across the full v2 project, I did 12 phone-a-friend consultations. Architecture reviews, code reviews, implementation reviews. The pattern was consistent: a second model would find things the first model missed. Not because one model was better than the other, but because they had different perspectives.
This feels like the future of AI-assisted development. Not one model doing everything, but multiple models checking each other’s work. It’s how human engineering teams work — code review exists because the person who wrote the code is the worst person to find bugs in it. The same principle applies to AI.
The final validation service redesign document was 1,166 lines. It went through 4 revisions. The appendix included full consultation summaries with severity tables. It was the most reviewed document in the entire project — more reviewed than anything I’ve ever written at an actual job.
Chapter 8: What I Actually Learned
A year of building the same thing twice taught me lessons that no tutorial could.
1. AI tools changed what I could build, not just how fast
V1 took 8 months and produced a working but unmaintainable system. V2 took 5 weeks and produced a production-grade service with comprehensive tests, design docs, CI/CD, a frontend, an admin dashboard, and observability. The difference wasn’t typing speed. It was the gap between using AI as a search engine and using AI as a collaborator.
2. Over-engineering is the default failure mode when AI writes code for you
Every AI model, when asked “what’s the best way to do X?”, will give you the enterprise-grade answer. Four summarization engines. Factory patterns. Strategy patterns. Dependency injection. These are real patterns with real uses, but not for a personal project with one user. The discipline of saying “no, simpler” is something you have to bring. The AI won’t bring it for you.
V2’s CLAUDE.md file — the instruction file that Claude Code reads at the start of every session — includes a constraint table. “No URL normalization.” “Magic link auth.” “LIFO queue.” “Single processor.” These aren’t technical decisions. They’re guardrails against complexity. Every time Claude Code proposes something fancy, the constraint table pulls it back.
3. Design documents beat code
V1 had zero design documents and 10K lines of code. V2 had 47 design documents and 15K lines of production code. The design documents were the real product. They forced me to think through decisions before writing code, and they gave Claude Code the context to implement features correctly.
The best feature of Claude Code isn’t code generation. It’s the ability to brainstorm a design, write it down, review it, and then implement against it. The design document becomes a shared contract between me and the AI.
4. Multiple AI models checking each other’s work is like having a team
I’m a solo developer. I don’t have colleagues to review my code. The phone-a-friend pattern gave me something I never had before: genuine code review from a perspective that wasn’t my own. GPT-5.2 Codex found critical bugs in architecture that Claude had helped me design. Not because Claude made mistakes, but because the reviewing model brought different analytical strengths.
Twelve consultations. Multiple critical bugs caught before production. Zero cost beyond API usage. For a solo developer, this is transformative.
5. Simpler is always better (but you have to earn that knowledge)
I couldn’t have built v2’s simple architecture without building v1’s complicated one first. The experience of maintaining an over-engineered system taught me why simplicity matters. The 5,739-line summaries.py taught me that one file should do one thing. The four unused summarizers taught me that unused code is worse than missing code. The dual-API architecture taught me that every network hop is a failure mode.
V2 isn’t simple because I’m lazy. It’s simple because I learned what complexity costs.
Epilogue
The podcast summarizer runs. Every day, it discovers new episodes from the podcasts I follow, transcribes them, generates summaries, and emails me the results. I read them over coffee. Five minutes per episode instead of ninety.
The kid is fine. He doesn’t know or care that his dad spent a year building and rebuilding a podcast email service. But I’m a better engineer for it. Not because of the code I wrote, but because of what I learned about working with AI.
The tools will keep getting better. A year from now, the workflow I describe in this post will probably look as primitive as copy-pasting from browser ChatGPT looks to me now. But the lessons will hold: start with design, keep it simple, get a second opinion, and build something you’ll actually use.
My podcast backlog is still infinite. But I don’t mind anymore. The summaries are enough.
Built with Claude Code, reviewed by GPT-5.2 Codex, and powered by more caffeine than any single human should consume.